Architecture
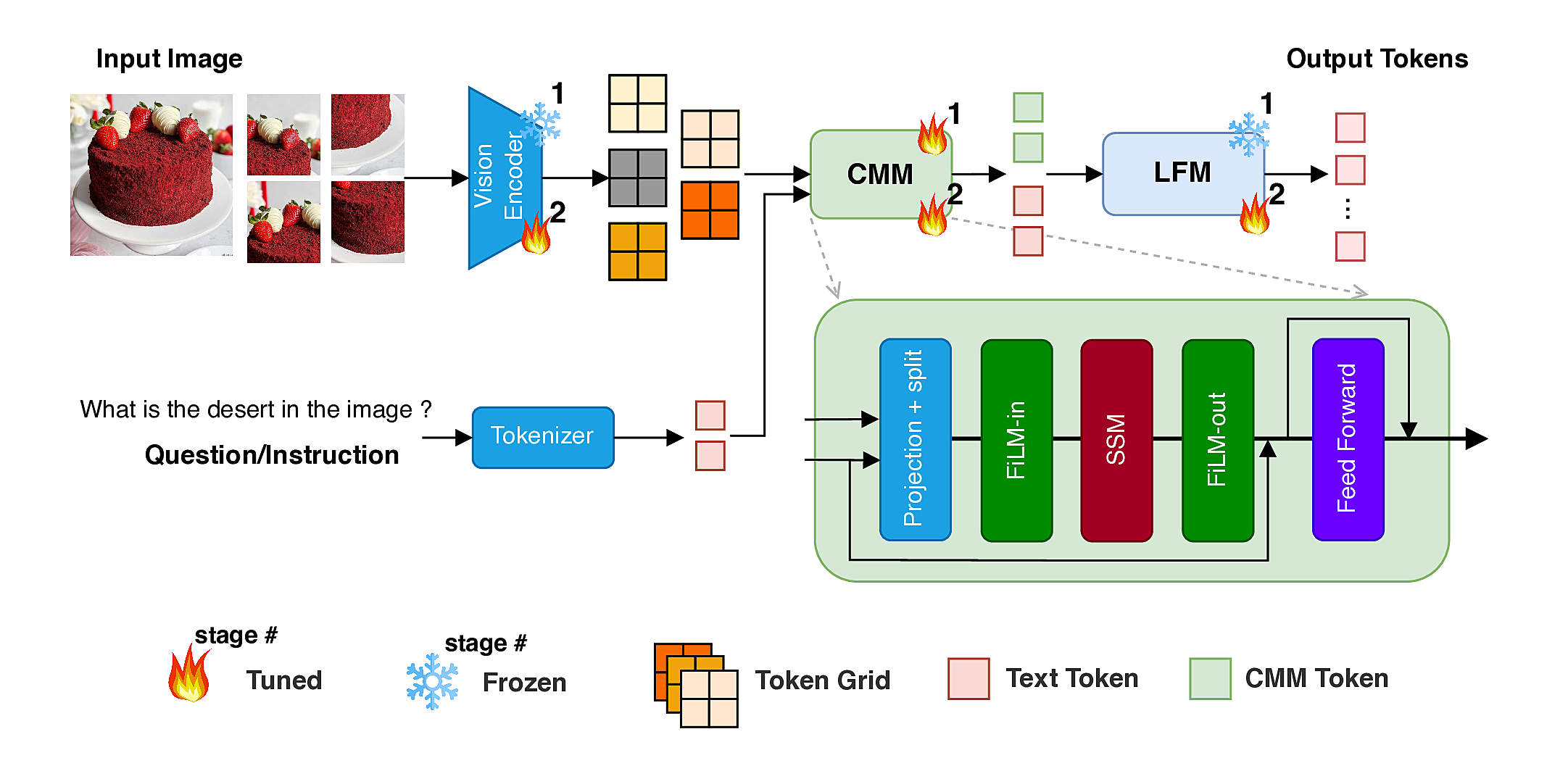
Main Components:
- 🎨 Vision Encoder (SigLIP) – extracts grid-level visual embeddings
- 🧩 Cross-modal Modulator (CMM) – token–grid correlation → FiLM → SSM → FiLM
- 🧠 Language Decoder (LFM2-350M-based) – multimodal reasoning and response generation
Training follows a two-stage recipe: (1) CMM warm-up with frozen backbones, and (2) end-to-end training.